Hello again dear reader! Pomf has continued to scale to wild heights, and so the cracks are starting to show. One such "crack" was the issue of cache refills. Read more on how I have just solved this problem, hopefully forever.
So, some background. Pomf has 4 edge nodes, each with 1TB of cache. The idea is simple behind this cache: When a user requests a file, we look at the cache first to see if we have the file already on-hand. If we do, we can just serve the file immediately. If we don't, this is known as a "cache miss", and the edge node must call home to the main servers (sitting under my bed) to retrieve a new file for the cache. This operation can be slow, especially for large files. This image below better illustrates the concept. (It's old, but still relevant. Just add one extra node to the chart.)
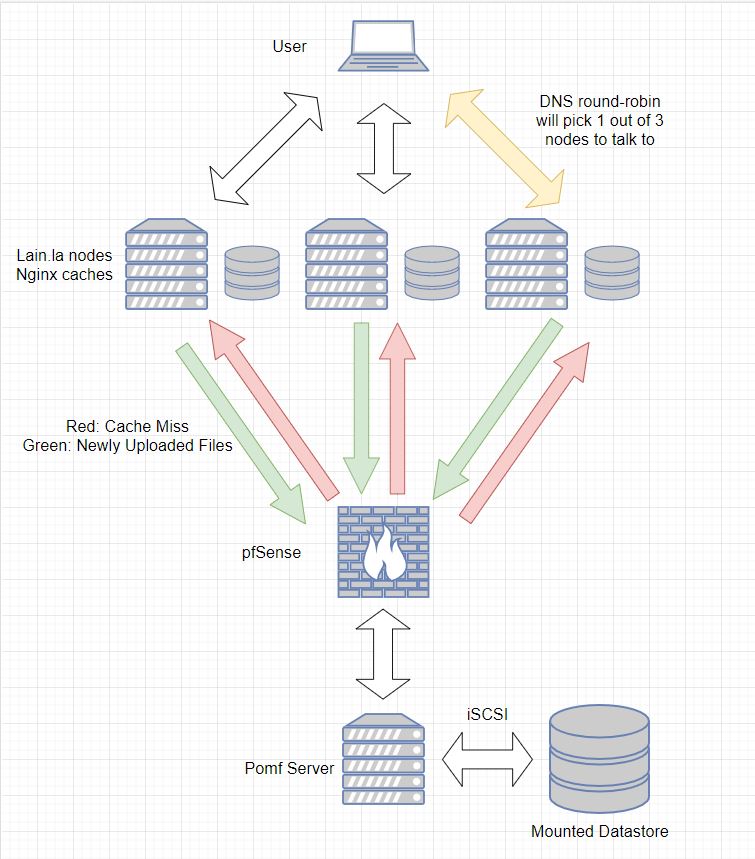
To orient yourself with the following discussion, please take a gander at the following link. If you don't understand it, don't worry, I'll give you some help right after.
https://www.nginx.com/blog/smart-efficient-byte-range-caching-nginx/
Gave it a shot? Good. Let's go over the various methods of caching that they discuss, in the light of Pomf:
- No caching whatsoever
- No caching whatsoever means that every single dang request is forwarded back home, so that every single file hits Pomf directly. This is no bueno, but was the first iteration of Pomf.
- Byte range requests
- Byte range requests were an improvement. Byte ranges are specified as an extension to HTTP, and allow us to request a part of a file. This part could be, say, the first 20MB of that file. So in the case of, let's say a 500MB video file, the browser might request a few dozen MB to start by using a range request (replied with the special HTTP code 206), and stream the rest over time. This helps with the responsiveness of the user's video session. The user can watch the video within a few seconds rather than grabbing the entire 500MB file.
- Caching via cache locking
- Caching via cache locking, combined with byte range request support, is where Pomf used to be before today. This would cache files locally on the edge node, but would require that the full file be loaded onto the disk before serving the byte ranges. So, the first request for a file would be slow as hell, but every request after that would be immediately served from the local cache disk based on what range the client requested. This worked great for 99.99% of requests because 99.99% of requests would be cached, but when you're dealing with a gigantic Pomf clone deployment, 0.01% is a lot of slow requests.
- Cache Slicing
- Cache slicing! That's what this article is about. This combines the beauty of byte range requests with caching and cache locking. Basically, we only need to lock the byte range "slice" of the file before allowing the requester to access the file. I set the slice size to 4MB, so we only need to wait for 4MB of data before we can serve the file, whether that file is 4MB or 400MB! This means cache misses will always be served as fast as 4MB can fill up (under 1 second on a good day), and the rest will just make its way to the edge nodes if the user continues requesting range requests for the file they requested, in the order they're required. So no more needing the entire file cached! Just 4MB will do!
These are the options I used to enable this:
slice 4m;
proxy_cache_key $host$uri$slice_range;
proxy_cache_valid 200 206 302 1m;
proxy_cache_valid 404 15m;
proxy_cache_revalidate on;
And then you need this in your location blocks:
proxy_set_header Range $slice_range;
proxy_http_version 1.1;
The cache validity stuff was set specifically because I want the server to stop serving slice ranges in the case of a malicious or illegal file. I used to do this by dumping the cache file via md5, but with cache slicing, there can be up to 256 slices for a file, making it impossible to clean them all.
This change has now been rolled out to all Pomf nodes. The cache had to be dumped on every edge node, so they're refilling all the new slices as of the writing of this article, at a rate of about 250mbps per.
Update 2 days later: The cache fills are largely complete, but addressing this many files at once hits the disks a little hard. We'll need to implement some improvements in this category to break past 1gbps per node reliably.