Quite the title. Last night we had a bit of a problem with the ol' Pomf clone. You see, something happened that I never expected to happen. Pomf hit its maximum outbound bandwidth threshold globally. This has never happened in the ~2 years I've been running all this.
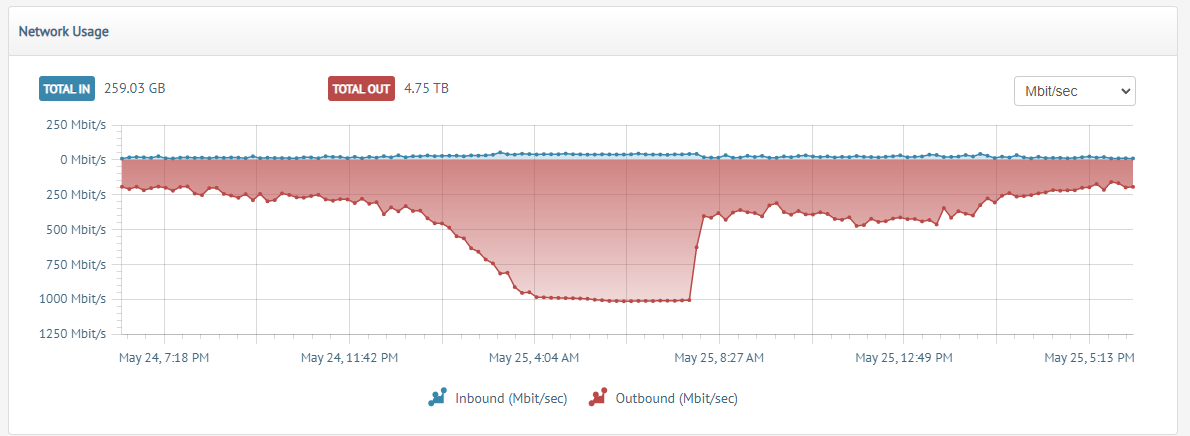
For the record, that's a whopping 1gbps outbound from a single node. The total network bandwidth was 4gbps actually because the bandwidth is capped at exactly 1000mbps (x4 for four endpoint nodes balancing all traffic).
So, in the words of David Byrne: Well - How did I get here?

A few days ago, I was alerted by a kind observer that an Indonesian Facebook group had been using my Pomf clone. That is documented here. Now, my usual response to this is "Let them come, nothing has taken down Pomf before in its current form!" And so, I saw spikes of maybe 200mbps-300mbps. Nothing crazy, that's equivalent to off-peak Reddit traffic before Lain.la got banned off of it. A day or two after, it hit 500mbps and I thought "Well, they're horny, but no big deal". Last night? 4gbps. Of Indonesian porn. It slammed overnight like a freight train. The inbound GET requests/TCP ACK traffic was 40mbit alone.
What exacerbated the situation was a cascade failure of systems. Because each node was beginning to overload, ping checks and HTTP checks started to crash out. Eventually, my monitoring script (documented here, although a tad out of date regarding IP targets) saw the weakest server in the cluster and said "Well shit, we got a bad node! Pull it!". This just shifted another 333mbps of traffic to each of the three remaining nodes. Naturally, this caused the script to see that another node was falling behind. "Well shit, we got a bad node! Pull it!", quoth the script. And now we were down to two.
Now, I'm no dummy. I wrote a failsafe into my script that prevents it from pulling more than 2 nodes and effectively blackholing myself in DNS. However, because each node was actually performing to the best of its ability and still failing, the script thought there was a problem other than just simple overload, such as a bad VM, bad network route, etc and did its job a little too well. You'll notice in the log screenshot below that Slice1 and Slice2 were doing okay, until Slice4 and Slice3 were unceremoniously killed in action. Then the pipes really gummed up.

So, what can we do about this? For starters, I had to blackhole traffic originating from Facebook. I don't like it, but maybe it will get them to move off that god forsaken platform. Then I dropped the max download speed to 24mbps (down from 40mbps) to get immediate relief. This really won't affect speed much except when streaming (e.g. 206 range requests) extremely high quality videos.
Other than that though, there's not much else I can do aside from increase capacity and cost. I was kinda secretly hoping that after the Reddit ban it would buy me time to roll out v2.2 and v2.3 of Lain.la's network architecture before hitting this cap, then we can work on an even more advanced caching architecture that would allow scaling to about 10gbps (separation of Pomf traffic from the entirety of my infra, dedicated Varnish caches with private IPs for the endpoints to call home to, etc.) without overloading my WAN link at the "Datacenter". You see, each endpoint node has to fill up its cache independently, so adding more nodes means more WAN traffic which I want to try to keep to a minimum, lest ol' Verizon ask for a handout. I could maybe squeeze in one more node to get to 5.12gbps total outbound capacity but that's a bandaid. I could also swallow my pride and just ban them but that seems like admitting defeat. Indonesians should get to rub one out too.
We'll just have to see how this goes. Maybe 4gbps is all Pomf really should have at the end of the day.
UPDATE: Even the Indonesian Government has taken notice.
-7666