Hello! It has been a while since I talked about networking, which is probably the most critical and advanced part of my infrastructure. Nobody's doing what I'm doing in this space, that's for sure!

To recap, these are all the iterations of Lain.la's networking/core infra that I've gone through:
- Lain.la v1.0 - Single VPN tunnel to a Ramnode box with a single host.
- Lain.la v2.0 - Multi VPN tunnel support to add as many template-built endpoint nodes that my heart desires, with multiple hosts and storage tiers.
- Lain.la v2.1 - Support for special tunnels (e.g. Slice5 for outbound/quiet traffic), outbound gateway groups with proper NAT, regimented backups, and more resiliency against abuse takedowns.
- Lain.la v2.2 - Wireguard, separated subnet for my VMs and free VMs, and mandatory HTTPS intra-tunnel.
- Lain.la v2.3 - Redundant networking for all hosts and servers, with multi-wan support (LTE failover)!
- Lain.la v3.0 - Separation of Pomf traffic entirely from the rest of the architecture, and a new caching system for all of it, possibly with haproxy for the actual edge nodes to distribute to intermediates or something. TBD!
I want to talk about v2.1 as it stands, and what I plan for v2.2/2.3 which is sort of already set. Also I'm going to add a new chart in the next article like I did for V2 after this article is done.
So v2.1 is currently the following:
- The same three ESXi hosts. Two precision towers, one lightning fast 2U R730.
- We now have a whopping SIX endpoint nodes / VPN tunnels. Wow!
- Got PFSense to 2.6. That's good. Broke shit though like my outbound gateway group.
- Lots of monitoring, inside and outside, for tunnel and service health.
- Tons of flash storage (6.8TB raw total).
- Tons of backup drives (Backup storage is currently 46TB).
- Big L3 switch doing all the core routing and switching.
- The R320 is still running DD-WRT and going like a champ.
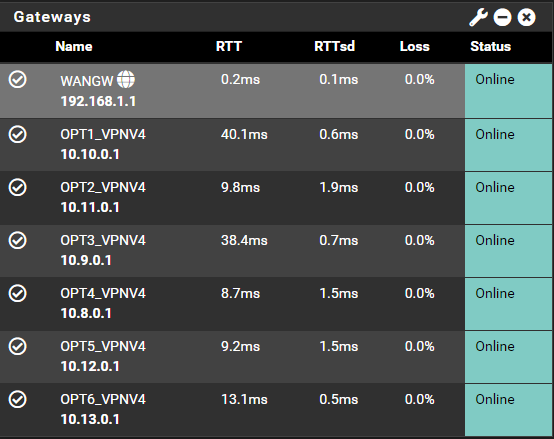
Gateway status:
The core concept around my architecture for an incoming request goes like this:
- HTTPS: Request -> Endpoint nodes -> Routed to PFSense via Nginx and SNI -> Routed to VM
- Pomf: Request -> Endpoint nodes -> Cache -> (if cache miss) Routed to PFSense -> Routed to VM
- Non-HTTPS Port: Request -> Endpoint nodes -> Masquerade mapping lookup -> Routed to PFSense -> Routed to VM
- Outbound: Request -> Routed to PFSense -> Gateway chosen based on network conditions -> Routed to endpoint node and exited
I unified all my endpoint nodes, regardless of their use case, with a standard template, meaning that any node can handle any request EXCEPT for the special tunnels I recently made to route more sensitive traffic. Nodes 1-4 are all bulk traffic, Node 5 is outbound and special traffic, and Node 6 is a special project inbound/outbound gateway.
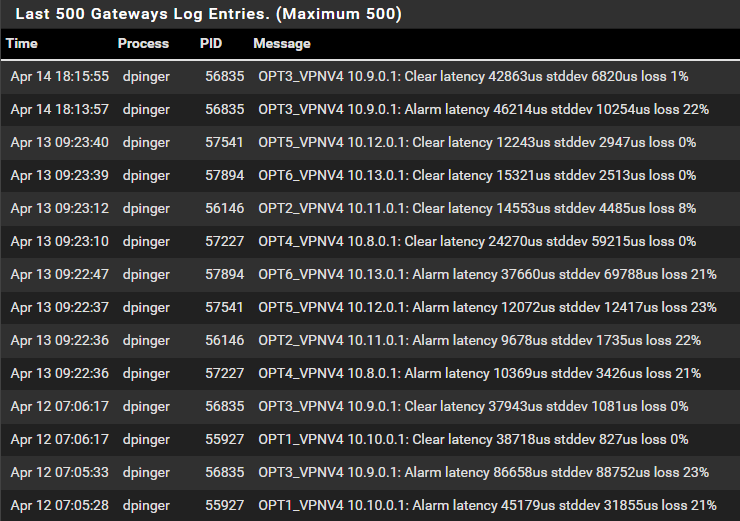
New historical logging for review:
So, v2.2 makes a lot of big jumps:
- Wireguard is the future. The speed and simplicity improvements are vast, and I have huge hopes for intra-tunnel bandwidth once I have it implemented. Of course, nothing is quite so simple... Maybe soon.
- Separated subnets with the firewall in between helps secure my things from all the people now inside my network.
- HTTPS intra-tunnel is just good to do. Don't want to end up like the NSA smiley!
Wireguard, when it is working, I am so excited for. If I can get 500mbps of upload through a tunnel, Pomf cache misses will basically not be a problem. Right now it can take up to 5-10 seconds for a full cache miss retrieval, that will basically go to 1-2. It's the last speed issue I have with Pomf.
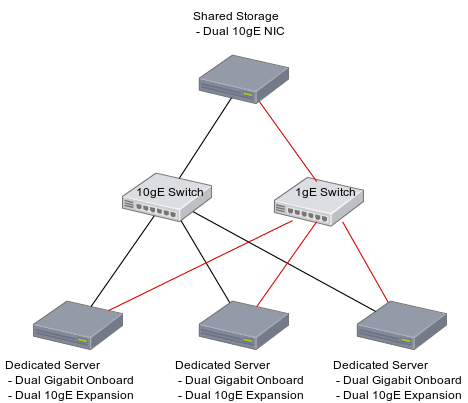
And v2.3 is a reliability improvement trying to remove more single points of failures, such as:
- 1 NIC per VLAN per host - this is bad, if a NIC blows up, that host is hosed.
- 1 Core switch - If that switch blows up (happened once already), all the interconnects are shot.
- 1 WAN link - If that goes, all of my VPN tunnels are cut off and can't get to the internet, so it's HTTP 502 abound!
I will add dual 10gb NICs and dual 1gb NICs (or better) to each host, and 1 of those leads on each server will go into each switch, which will be trunked together. Oh, and the R320 will get two uplinks, one into each switch, to preserve the WAN connection if a single switch dies. Basically this is so that if a switch blows up everything just keeps going with the redundant links.
The dual WAN link will be handled by LTE. Might not be fast, but better than nothing. I got the chance to play with T-Mobile LTE and got 40mbps upload which is... oof. But again, better than nothing. Needs a script to do a failover in case of emergency and then the actual subscription implemented.

Next article will be the new chart.