Hello again! It has been a while since I wrote a new article, only because most things have been stable. We've been through another maintenance cycle (which is really just patching and certificate rotation these days) and I've documented my procedures and setup processes more so than ever. Here's some highlights of the updates:
Executables Policy on Pomf
My main goal with file upload restrictions on Pomf is to prevent the proliferation of directly executable files, in case they are being used maliciously. Essentially, a user should not be directed to a hotlink of my site to deliver a payload of anything that could be handled specially by an operating system. Examples are .exe files, HTML files, .zip files, .svg files, and, newly, .apk and .jar files. I continue to adjust what is and is not allowed on my Pomf clone to adhere to this basic policy of preventing special or direct execution of files from clients.
New Hentai Nodes
My Ramnode hentai nodes were reliable, but the cost per GB was not quite as good as my new host's. On Ramnode, I could get about 2.5TB of storage for $40 a month. On my new host, it is a full 6TB for $36 a month. I have begun the process of shifting all of my Ramnode hentai nodes to BuyVM because of this price difference. I will be going from 8 325GB hentai nodes to 3 2TB hentai nodes. This also makes maintenance far easier with 5 less VMs to maintain. Oh, and I've never posted my H@H stats so here you go.
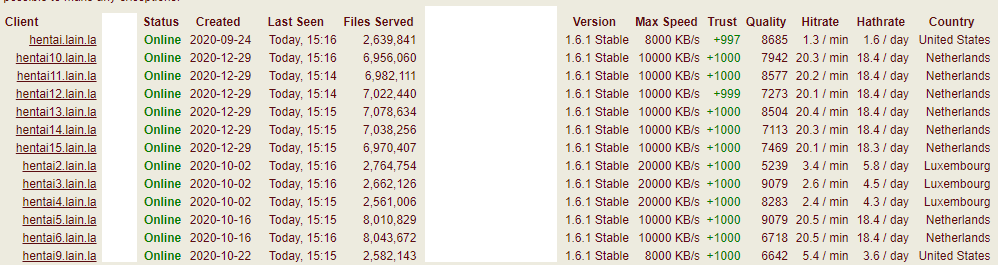
Dynamic statistics can be viewed publicly here: https://hentai.lain.la/d/5lpcAMKGz/hath-client-network-health?orgId=1&refresh=1m. Special thanks to this wonderful person who I based the metrics and pollers on, and then improved slightly: http://patchouli.dekarrin.com/articles/metrics.html
Vomitchan on lain.la
An IRC bot named Vomitchan (https://github.com/mariari/vomitchan) written by a friend has been moved to my infrastructure for a few IRC networks. Despite being placed on the slower HDD RAID5 array, the speed increase is significant and should also improve reliability, as well as being automatically included in my backup regimen.
A strange, new bug (FIXED!)
I've discovered that outbound routing via Pfsense will break if the last restarted tunnel is not OPT1 (the first interface out of four OpenVPN interfaces and the one selected for outbound NAT). I don't know why, but I have it in my back pocket to figure it out. Before, outbound routing would just break and I'd have no idea why. I would just cycle all the OpenVPN tunnels in a mad attempt to fix the problem which usually worked. Now, at least I have an indication as to what the problem is. Inbound routing is entirely unaffected. My layout of OpenVPN tunnels in Pfsense is pretty much cookie-cutter from the initial template.
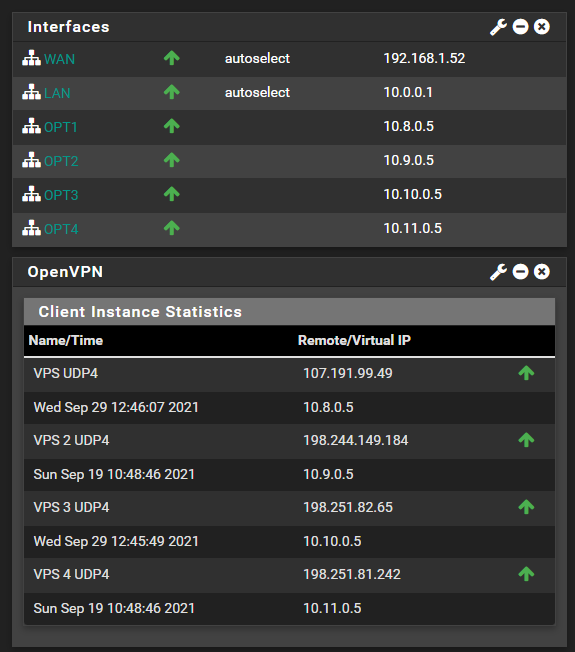
Fixed as of 10/30/2021! The issue was that I didn't have Outbound NAT rules for EACH interface - just the active one. PfSense is smarter than I thought - it will automagically adjust the outbound default gateway on a tunnel failure - using that behavior to my advantage I just added overlapping Outbound NAT rules tied to each individual interface so no matter which tunnel traffic is going through it will always know how to proceed.
More redundant hardware
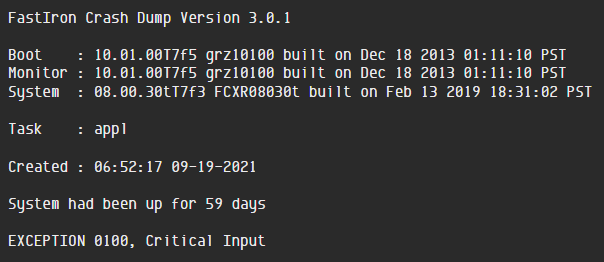
A switch failure caught me by surprise one morning. The most enterprise-y and powerful thing in my entire architecture blew a gasket. I was not pleased. Turns out the OS crashed, and I never committed my VLAN changes to memory which caused host communication between the nodes to fail. After fixing that permanently, now my exposure is just the OS crashing again which is disruptive but will at least auto-recover. I bought another ICX 6610 switch and configured it as a backup, just in case. Also - I bought an extra power supply for my NAS considering that only has one. I also bought a hot spare WD 8TB Red HDD which is what my RAID array is stacked with. Here's the extremely helpful error message from the switch:
Full Backup Cycling
My backup structure is probably the most robust of any out there. I have full compliance to the 3-2-1 rule, which if you are not familiar is:
- Three copies of all data
- Two different backup targets
- One offsite backup target
My system got it's full first test when I cycled my offsites for the first time. My backup structure is this:
- Almost all critical VMs are running on a RAID array of some kind - I know this isn't a "backup" but it is resiliency and deserves some credit.
- I have free licenses to Veeam, an enterprise backup system. It provides encryption, deduplication, incremental backups, and full automation and integration into my hypervisors. This runs twice a week, Saturday and Wednesday, and keeps at least six different incremental backups. They are offloaded to a dedicated 8TB external USB3 hard drive.
- Every three months or so, I grab my powered off, 14TB external USB3 HDD from a secured location, and I rotate all the backups from the NAS, Veeam, and my personal backups on it with current versions. After backups are done, this then goes right back into it's safe storage spot, powered off, in a locked drawer on the second floor of a steel building, behind perimeter biometric security and a sturdy door to which I have the physical key to. Yes, I'm serious.
Gitlab Emails Fixed
Yeah I broke the outbound SMTP system for Gitlab which is based off a custom fork of the Protonmail Bridge. I forgot that it runs in a screen session and when I rebooted it, (uhh... 65 days ago?) that service never restarted on its own. Sorry. That has been fixed and documented. Outbound email should work now. Inbound mail never worked with the system based off Hydroxide but that can be revisited later. See https://github.com/emersion/hydroxide for more details.
HTTP/2 Support
Lain.la now supports HTTP/2 across every single site. This was literally as easy as changing the listen directive from "443 ssl" to "443 ssl http2" on every server block on every edge node.
Cache Regeneration
(For those who have not noticed - I am literally just updating this post consistently through October so yeah.)
I can no longer do my usual method of cache regeneration due to the incredible demand for Pomf bandwidth (800-1000 mbit today!), as it just can't keep up. I do cache regenerations to remove files that need to be removed (use your imagination here). The Nginx cache just has a mapping in memory as to what file is what, and it's just a bunch of randomly generated filenames in the cache folder. Easiest way to ensure a file is removed? Dump the whole thing and let the cache rebuild. But now with 25-50GB of content cached at the edge, regenerating all that SUCKS. So, I need to write a hash file comparison system to check a file hash against all the nginx caches and selectively remove content as needed (As of Nov 24th: Done!) Otherwise, this happens (that's output to the edge nodes in megaBYTES:
New VPN Tunnel Health Checks
Previously there was no real great way to check the health of my VPN tunnels or the firewall state on an end node, but now I have a nice way to do so, and it's published to Uptime Robot. It will tell me if a VPN tunnel collapses or if I forget to re-initialize the iptables rules after doing a config change (this has happened more than once...).
Check Uptime Robot for the new "VPN Tunnel Checks".
Metrics!
I'm super happy to do a metrics post. I brag about how large lain.la has gotten but never on "paper". So, here we go!
- Lain.la has 512GB of DDR4 memory in total. It currently uses 115.1GB.
- Lain.la has 111.04GHz of CPU resources in total (this is an arbitrary metric acquired by multiplying cores by clock speed). It currently uses 2.34GHz at idle and about 6GHz during certain situations.
- Lain.la has about 14.5TB of storage in total, mixed between local drives and RAID arrays, high performance and low performance. It currently uses 2.52TB. There is more storage available as the LUN on the NAS is only 10TB allocated and we can probably get away with 14-15TB of allocation for a total of 18.5-19.5TB.
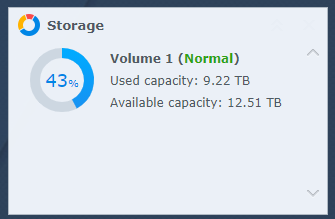
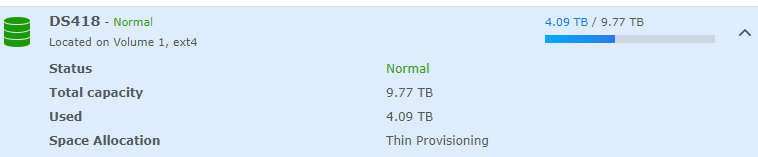
- Lain.la consists of 30 virtual machines on core infrastructure, 20 of which are directly under my control. Another 16 exist in the ~cloud~ across three providers for a total of 46 VMs. It consists of four physical servers (3 hypervisors 1 router).
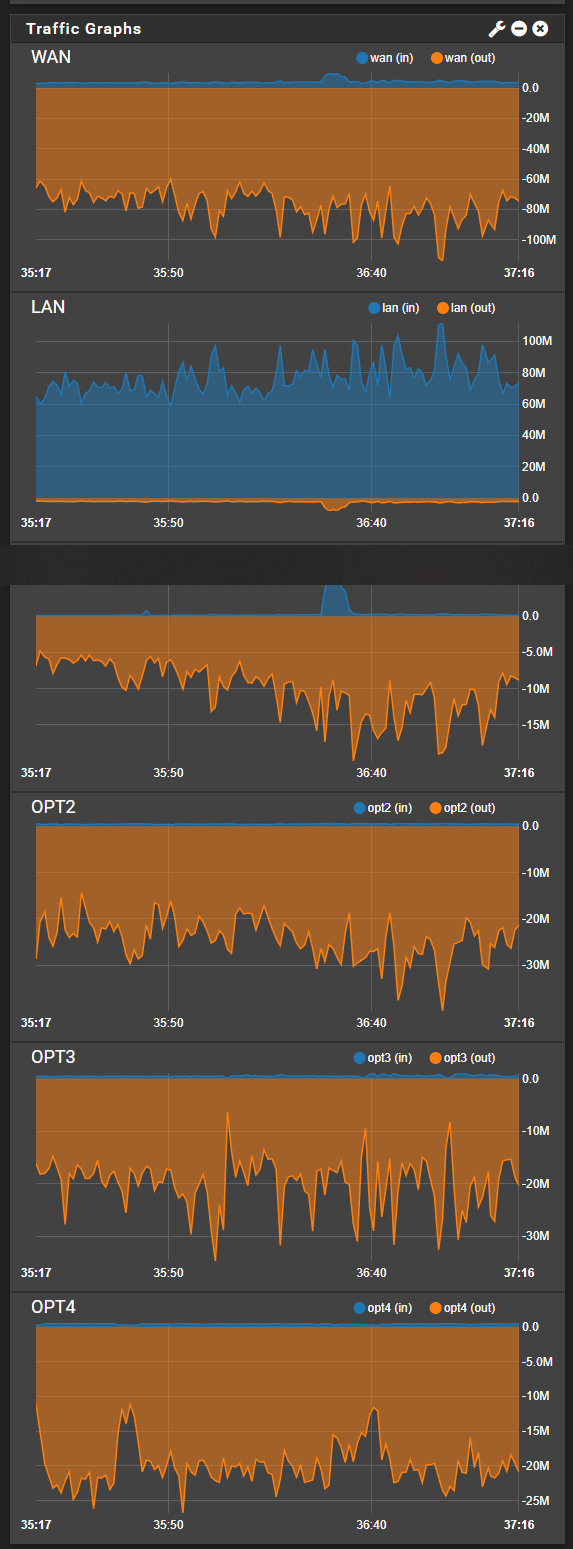
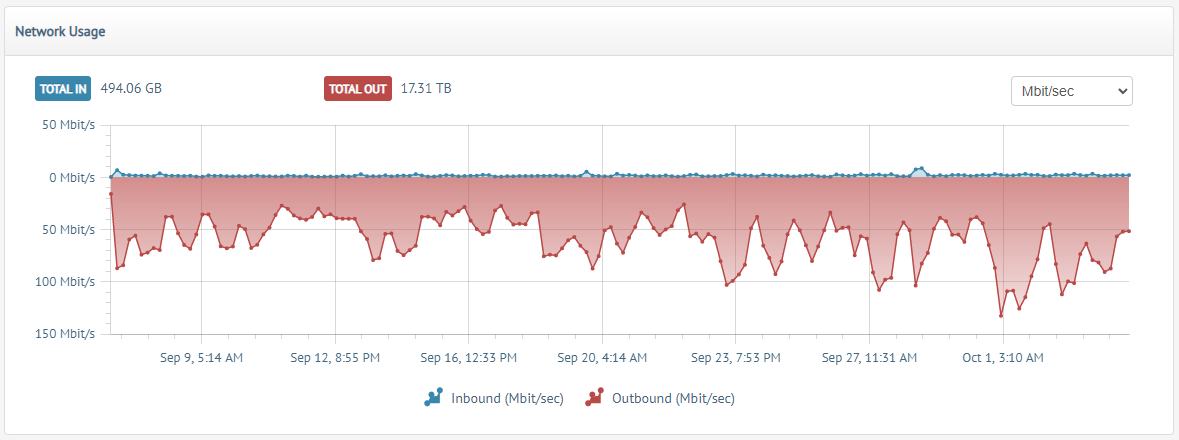
- Lain.la has pushed a whopping 68TB of outbound data (+4TB of seeding data from the seedbox on the master node for a total of 72TB) in the past 30 days, as extrapolated by looking at the usage of one node and multiplying by four (DNS round robin should be near perfect balancing, 25% load per node in the cluster of four that I have now). Here is a graph of just 1 node:
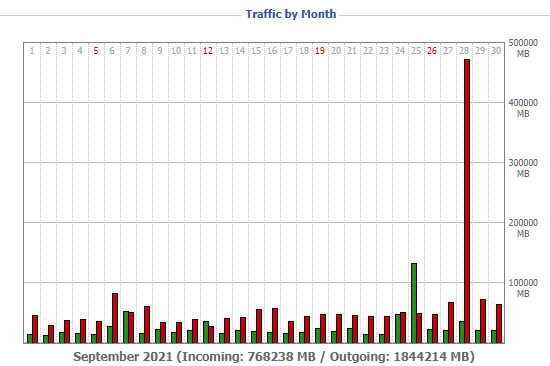
- The caching system has a cache ratio exceeding 30:1, as my actual core infrastructure outbound metric was only 1.8TB and some of that may have been unrelated traffic. There was also a bug in the cache that pushed 500GB of data out unnecessarily, so the ratio is likely somewhere in the neighborhood of 40:1 on a good month. Here is a graph of my router's bandwidth (remember - data only goes through the router when the cache is missing a file):
- My lain.la monthly costs have dropped a little bit! It used to be a flat $200 a month, now it is $185.50. Check https://infrablog.lain.la/infra-costs for up to date stats, I update this article anytime there is a monthly cost change. And no, I'm still not taking donations. You can send me an email though, it's worth more to me and I will actually answer :)
- Pomf gets it's own mention since it has driven 95% of the traffic, resource usage, and innovation that I've had to do to keep it running. I currently host 395GB of active content, across 29,620 files. Here's an export of the mounted directory's current disk space. Plenty to go!

- If you are not familiar with Uptime Robot, I use it for external monitoring of almost all of my services. I'm extremely proud of Pomf's uptime statistic for the past 90 days, which is 99.996%. That's slightly better than 4.5 nines (https://en.wikipedia.org/wiki/High_availability#Percentage_calculation), or under 6 minutes of downtime for the past 90 days. Link: https://stats.uptimerobot.com/7Wv64Fm2KK
Well, that's all for now! Hope you enjoyed. If I don't post again, happy Spooktober. -7666