This article will be an absolute monster, so here are jump links to each section in case you want specific sections:
- Section A: Pomf Infrastructure
- Section B: Nginx and Caching Hierarchy
- Section C: Redundancy Vs. Load Balancing Vs. Failover
- Section D: Lain.La Witness Failover System
To start, let's grab some context on why this was all needed, then we'll dive in. I mentioned a bandwidth image in my previous article that was disturbing. I now have an even better one:

So, this chart doesn't show the lain.la bandwidth charts because those are broken (not my fault). This shows when I was able to cut traffic over to the new node (alt.lain.la) and what that traffic was. At the time the traffic value was about 120 mbps sustained, peaking to 240 mbps. This was more traffic than I had ever seen before, but was well within normal parameters of what I had built. This traffic was from a subreddit where videos are posted.
Then, uhh, August 3rd happened. One of those reddit posts went nuclear and everybody wanted to get their hands on the video I was serving. That was a sustained spike of almost 500 mbit. I saw 800 mbit at one point on the instantaneous network graphs. It was nuts. My SSH session would regularly hang while the server was busy trying to serve content. The first cliff drop you see there was when I put lain.la back into rotation alongside alt.lain.la to begin proper load balancing. From there I worked hard to get Node #3 up, ovh.lain.la, and put that into rotation as well, and that's where we are today.
Pomf is, by far, the most complex and troublesome service I run. It is also the most popular.
(Note: alt.lain.la and ovh.lain.la are internal names. Don't try to punch these in a browser, they won't work!)
Pomf Infrastructure
The easiest way to describe how Pomf works is by reading the source code! https://github.com/pomf/pomf
Pomf is just a php frontend for a file uploader. It has a few features which are useful (extension blacklisting, MIME type blacklisting, deduplication via hashes) but that's all. My Pomf infrastructure is designed to reduce the load on the server physically hosting Pomf, so let's make ourselves a chart and explain it:
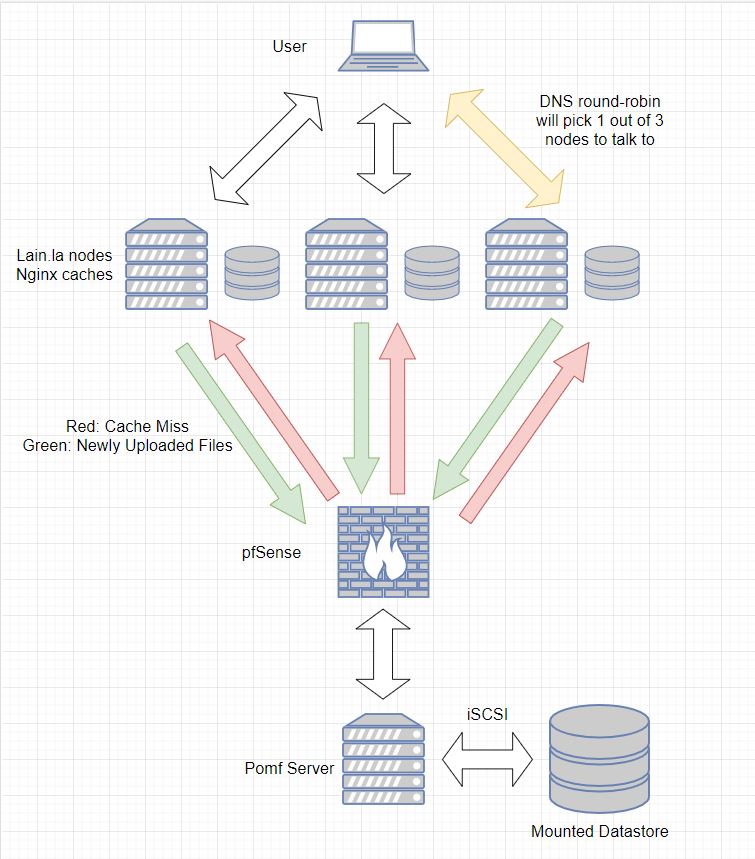
Basically what you are seeing here is how a file requested by a user is served. Logically speaking, here's how this goes:
- A user requests a file.
- That request goes to one of the three lain.la nodes (assuming all are functional).
- If the file is cached, great! Serve the file.
- If the file is NOT cached, use proxy_pass to head back, over the VPN tunnel, to request the data on the Pomf server.
- The Pomf server will read the file into memory from the datastore and serve that file via it's own Nginx web server.
Nginx and Caching Hierarchy
Caching is the lifeblood of Pomf. I have Verizon FIOS gigabit fiber, but I do not want to rock the boat more than I have to with them, so minimizing bandwidth keeps everyone happy. My caching solution covers 99% of all file hits and traffic, and the remaining 1% slip right under the radar. It also saves on CPU, because AES-256 eats CPU power to encrypt/decrypt the data across the VPN tunnels, even with AES-NI. It also protects against ISP failure, because the cache is so large it will serve practically the entire active content library of Pomf and rarely, if ever, call back home for data.
Here's how the cache is set up, on a high level:
https://ghostbin.lain.la/paste/279o7
Let's go over these options and what they do:
- proxy_cache_path - This is the core configuration of the proxy. I'm telling it to use 2 level caching, use 50MB of memory for lookups, max out at 100GB, and don't use files that are more than 1 day old.
- proxy_cache - This is located inside the Pomf server block to tell it to use the cache we just set up above.
- proxy_cache_use_stale - If Pomf is screwed up back home, serve stale data anyway. At least it's something.
- proxy_ignore_headers/proxy_hide_headers - I don't recall why I had this, but it keeps the cache working somehow.
- proxy_buffering - Buffer files while serving them (e.g. use maximum speed to retrieve the file but keep the limiting on for the client)
- proxy_force_ranges - Allows the use of 206 Range Requests (especially important for videos)
- proxy_cache_min_uses - Tells the proxy to only cache something after it has been requested twice.
- proxy_cache_revalidate - I probably don't need this in there because Pomf data is static.
- proxy_cache_lock - Don't make multiple requests for a file from the backend if it's being requested multiple times simultaneously (protects against bursty traffic)
- proxy_read_timeout - Time out after 90 seconds. Probably too high.
- proxy_cache_valid - Serve proxy data for 200, 206, 302 HTTP response codes. The 206 is important there.
- proxy_cache_max_range_offset - Do not accept range requests for files under 32MB. Just send the whole file. I need to revisit this setting.
There is some other secret sauce going on here that I'm not willing to share at this time, but it does not functionally change how caching works.
For more info: https://nginx.org/en/docs/http/ngx_http_proxy_module.html
Redundancy Vs. Load Balancing Vs. Failover
With Pomf and caching out of the way, let's talk about having multiple caching nodes and how I set up what I did. These caching nodes are also providing endpoints for all other services, but we'll talk just in the context of Pomf. First, some definitions. These three terms above are NOT the same thing:
- Redundancy - The ability for a system to tolerate a failure seamlessly.
- Load balancing - The ability for a system to spread the workload around multiple nodes/endpoints to prevent overload.
- Failover - The ability for a system to move traffic from a failed node to a working node.
Pomf.lain.la currently has all three, but these are all operating at different layers.
- Portions of the Pomf service itself are redundant because there are multiple failure scenarios that it can tolerate and continue to function, such as the loss of an endpoint node.
- Pomf balances its traffic across three nodes using DNS A record round-robin. Check "dig lain.la" to see the three nodes in action. Query it multiple times to see the records shift!
- Pomf can failover a bad node to the remaining good nodes via the Witness Failover System I wrote (discussion below). It will take a node out of rotation if it determines there is a failure by removing its corresponding A record.
So, for the sake of argument, let's work through this logic by simulating a failure!
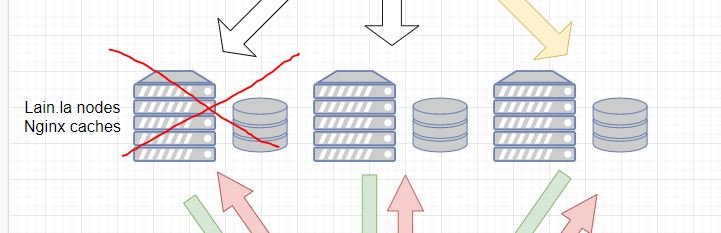
In this situation, Node 1 has failed. Pomf has redundancy because Nodes 2 and 3 are functioning. Pomf has load balancing because there are still two nodes functioning, handling the traffic together. Pomf has failover because the dead node will be yanked from DNS within about 10 minutes of its death and traffic moved to the other two nodes entirely automatically (in the failover scenario I have chosen the STONITH method - Shoot the other node in the head).
Lain.La Witness Failover System
The last part! This is an entirely custom system I wrote to protect against the critical pitfall of A record round-robin - If you have a dead node, traffic will still be served to it! This is why nobody uses it except when they have the ability to remove a node automatically. Even then, people don't use it because they can't control DNS caching (TTL helps a bit) and other nameservers. They'll opt for HAProxy instead. I won't because of time and complexity constraints.
The code for this system is here in it's entirety. Last updated: April 8th, 2023. This program has run thousands of times by now, checking once a minute, for failures on any of my three four nodes.
https://ghostbin.lain.la/paste/usbt7
It is written using:
- Bash
- Python
- PyNamecheap
- Cron
- Text Files
That's it. Now I'm sure I'm going to hear some of you going "WHY DIDN'T YOU DO IT IN LANGUAGE X / Y / Z / A / B / C / WHATEVER"??? Because I didn't, that's why.
A high level overview of the code is as follows:
- Check HTTPS, Ping, and SSH on the node. If any one of the three fail, assume the node is degraded in some fashion and log a strike against it.
- If 4 or more failures are detected within one hour, we haven't already killed three nodes, and the node isn't already dead, kill the node and log it.
- Run a Python script that utilizes PyNamecheap to delete the A records of the node via Namecheap's API. I didn't include these files because they contain API keys.
This code is dead simple, easy to maintain, predictable, and reliable. I follow the K.I.S.S (Keep it simple, stupid) philosophy in everything I do because I am lazy and, frankly, I'm going to forget how all this works in three months.
Can you believe I do this all for free?*
*I don't take donations and likely never will. However, not including capital and power costs, lain.la has a recurring cost of $240 a month. Latest costs, See: Infra costs